El contexto nos permite tener un historico de lo preguntado, y así adaptar nuestra respuesta pero este es limitado, según lo definamos como hemos podido ver al crearlo.
context_t *iniciaContexto(modelo_t *modelo)
{
paramContext_t parametrosContexto = llama_context_default_params();
// Optimización para OpenBLAS en CPU
//parametrosContexto.n_ctx = 2048; // Tamaño contexto
//parametrosContexto.n_batch = 2048; // Tokes a procesar para llama_decodee.
parametrosContexto.n_ctx = 512; // Tamaño contexto
parametrosContexto.n_batch = 512; // Tokes a procesar para llama_decodee.
// Crear el contexto ligado al modelo
return llama_init_from_model(modelo, parametrosContexto);
}Vemos en el código que serán 2048 bytes, pero según vamos realizando iteracciones se va llenando, así que llegado ese momento
// Analizamos el espacio del contexto
int n_ctx = llama_n_ctx(contexto);
int n_ctx_usada = llama_memory_seq_pos_max(llama_get_memory(contexto), 0) + 1;
if (n_ctx_usada + miBatch.n_tokens > n_ctx) // Sobrepasamos el contexto, por lo que debemos limpiar o restructurar.Una vez que vemos que no disponemos de más contexto podemos realizar tres cosas:
- Salir del programa porque no tenemos más espacio, no es lo más normal a utilizar.
- Limpiar el contexto por completo, acordandonos de poner el rol del sistema para que se vuelva a comportar con el ROL definicdo.
- Rotar perdiendo solo lo más antiguo «Ventana Deslizante»
La primera opción es muy sencilla, pues valdrá con realizar un exit(x) el segundo también es sencillo y sera limpiar el área del contexto por completo y reiniciar la inferencia desde el principio.
llama_memory_seq_rm(llama_get_memory(contexto), 0, -1, -1); // Borra todo el área del contexto.
free(prompt_formateado); // Limpia volvemos a inferir
inferencia(rolSystem, prompt, modelo, contexto, miSampler,vocab); // Volvemos a realizar la inferencia.La tercera opción y la que consideramos más apropiada pues no es compleja y nos da mucho juego es la técnica de la Ventana Deslizante (Sliding Window) que en lugar de borrar todo cuando el contexto llega a su límite, aplicamos una poda selectiva:
- Preservamos el ROL: Los primeros tokens (instrucciones del sistema) nunca se borran.
- Rotación: Borramos un bloque intermedio y desplazamos los mensajes recientes hacia atrás usando «llama_memory_seq_add»
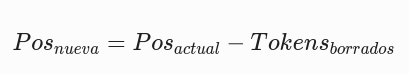
Lo primero es conocer los Tokens que utiliza la definición del Rol-System ya que muchas veces es pequeña o nula, pero por ejemplo en la creación de un agente como veremos más adelante es bastante amplia.
// Antes de nada debemos saber cuanto ocupa el Rol del sistema.
mensajeChat_t rol_System[] = {{"system", rolSystem }};
// Calculamos los tokens del ROL,
int32_t bytes_ROL = llama_chat_apply_template(llama_model_chat_template(modelo, NULL), rol_System, 1, false, NULL, 0);
// Buffer temporal para el ROL formateado
char * prompt_ROL = malloc(bytes_ROL + 1);
llama_chat_apply_template(llama_model_chat_template(modelo, NULL), rol_System, 1, false, prompt_ROL, bytes_ROL);
prompt_ROL[bytes_ROL] = '\0';
Contamos TOKENS usamos NULL en el buffer de tokens y 0 solo cuenta
int32_t tokens_ROL = llama_tokenize( vocab, prompt_ROL, bytes_ROL, NULL, 0, true, true ); // add_especial es true porque el ROL abre la secuencia.
free(prompt_ROL); // Limpiamos memoria temporal del ROL que no sera necesariaCon el dato de los tokens del Rol-System ya podemos realizar una rotación, antes definiremos también cuantos se echan hacia atrás, podemos ver un ejemplo grafico de 2 tokens para el ROL y 10 en total.
ESTADO 1: Contexto Lleno
[ S1 | S2 | T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 ] <-- ¡Lleno!
^----^ ^--------------------------------^
SYSTEM HISTORIAL DE CHAT
ESTADO 2: Aplicando Sliding Window (Borramos el 20% antiguo)
[ S1 | S2 | -- | -- | T3 | T4 | T5 | T6 | T7 | T8 ]
^-- Hueco creado (borramos T1 y T2)
ESTADO 3: Compactación y Desplazamiento (Shift)
[ S1 | S2 | T3 | T4 | T5 | T6 | T7 | T8 | N1 | N2 ]
^----^
NUEVOS TOKENSEn código quedaría de la siguiente forma
// Técnica avanzada de "Sliding Window" (Ventana Deslizable).
int32_t n_tokens_a_borrar = 256; // Definimos bloque a borrar
// Límites de la "poda" p0(Despues del ROL) p1 + borrado
int32_t p0 = tokens_ROL; //Los TOKENs necesarios para el ROL, desde donde borraremos
int32_t p1 = tokens_ROL + n_tokens_a_borrar; // Hasta donde borramos
llama_memory_seq_rm(llama_get_memory(contexto), 0, p0, p1);
// Movemos lo que quedó al final hacia atrás para cerrar el hueco
llama_memory_seq_add(llama_get_memory(contexto), 0, p1, -1, -n_tokens_a_borrar);
// Continuamos con la inferencia llamando a llama_decode.Y ya nos queda que lo dejamos para el próximo la generación del agente, que veremos que lo único que añadiremos es una definición correcta del Rol-System, y las funciones agenticas.