Continuamos con opciones más avanzadas de «wfuzz» pero que son bastante interesante para poder generar nuestros comandos para ayudarnos en nuestras tareas de pentesting y capturas de bandera.
Filtros
Aunque lo pongamos en esta segunda parte el filtrado de resultados es muy importante en ya que sino tendríamos mucha información que evitaría que viéramos la información que realmente nos seria de utilidad.
Los filtros pueden ser que eliminen esa información o que visualice:
Por ejemplo si estamos lanzando una búsqueda de directorios para ver por ejemplo el sistema, solo nos interesara ver las paginas que den 200-OK y no las que den error 404-Página no encontrada.
- –hc o — sc <código respuesta> oculta «hc» o visualiza «sc» el código especificado. Podemos especificar varios códigos separandolos con comas.
- –hl o –sl <numero de lineas> Por el número de lineas en la respuesta.
- –hw o –sw <palabras> Por número de palabras
- –hh o –sh <caracteres> Por numero de caracteres
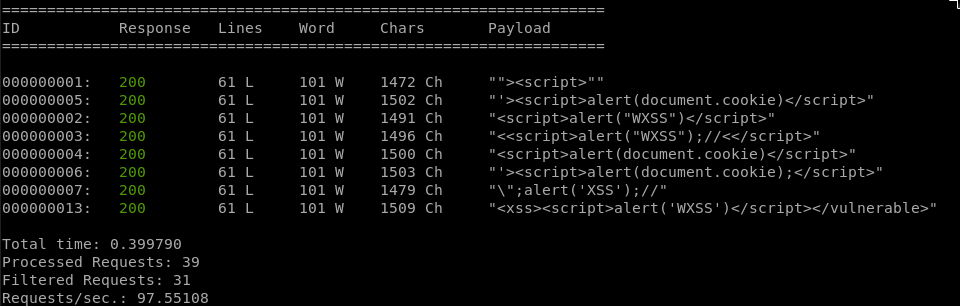
Estos son filtros simples o de respuesta, pero podemos complicarlo un poco más con expresiones regulares usando «–hs o –ss <filtro>»
Esto nos ayudara mucho en la búsqueda de usuarios por fuerza bruto o la localización de Injections-SQL como veremos cuando expliquemos los ejemplos.
Los filtros podrían complicarse mucho más con «–filter» que nos permitiría añadir lógica condicional, pero esto lo dejamos para una explicación avanzada a tratar más adelante o si lo deseas puedes ver el manual de los filtro pero como apertura de boca:
// Codigo "200-OK", pagina correcta y la respuesta tiene más de 100 lineas y menos de 200tenemos más de 200 lineas.
--filter "c=200 and (l>100 and l<200)" // Codigo "200-OK", pagina correcta y tenemos más de 100 lineas y menos de 200.
// El contenido tiene el payload, util en análisis XSS.
--filter "content~FUZZ"Ademas estos filtros también los podremos usar para filtrar los payloads con «–slice«
Scripts
Con los scripts logramos que wfuzz sea algo más que un escaner y nos permite incluso actuar explotando vulnerabilidades por ejemplo.
Para conocer los script de que disponemos usaremos el comando wfuzz -e scripts, que como podemos ver los separa en tres categorias:
- Activos: Transforma la petición lo que nos permite probar vulnerabilidades.
- Pasivos: Solo analiza la respuesta y petición pero no la transforma.
- Descubrimiento

Para conocer algo más de lo que realizan los script ejecutaremos «wfuzz –script-help=<nombre script>«
Vamos a explicar algunos de ellos y como siempre lo mejor es probarlos uno mismo sacando conclusiones de para que nos pueden servir.
robots (Analisis de los ficheros robot.txt)
Recoge el fichero robots.txt, que se pasa como payload ya que podremos varios y de distintos nombres, lo abre y analiza realizando la petición de estos directorios aun cuando el fichero robots.txt indique que no debe acceder.
Para el que no conozca que es el fichero robots.txt comentar que es un fichero que ponemos en el raíz para evitar que se rastree o indexen directorios en los buscadores y ese es el problema. Tenemos un fichero que podemos leer fácilmente y que nos indica que ficheros y directorios no queremos indexar (vamos que nos interesa se mantengan privados) y ya sabemos que la naturaleza humana nos dice que si eso no debe verse nos pica rápidamente la curiosidad y nos ponemos a investigar.
Sintaxis de robots.txt
User-agent: Indica los motores de búsqueda a las que se aplica las reglas siguientes (* para todos) Lista de robots de búsqueda web.
Disallow: Indica que no se puede acceder ni rastrear. Pudiendo usar patrones.
Allow: Lo contrario, así podriamos poner una regla restrictiva que Allow libere.
Un claro ejemplo lo vemos capturando la bandera de Mr. Robot que lo primero que hacemos es ver el fichero robots.txt y encontramos el nombre de dos ficheros (en este caso no ponía Disallow pero dio igual) y porque no mirarlos, descubriendo la primera bandera y un fichero de claves que nos serviría para las siguientes pasos.
wfuzz --script=robots -L -z list,robots.txt http://www.webscantest.com/FUZZ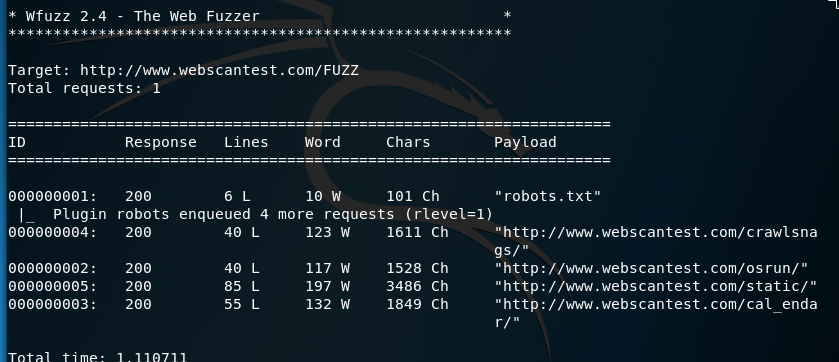
Si sabemos de otro fichero con la misma sintaxis que robots.txt bastara con cambiar o añadir el nombre a la lista.
Lo mismo que con robots.txt podemos hacer con el script sitemap que parsea el fichero sitemap.xml.
Links (Parseo HTML)
Nos localiza los links parseados del fichero HTML, esto nos puede servir de ayuda para localizar enlaces rotos en nuestras páginas web (no todo tenia que ser pentesting) indicando que solo nos muestre los 404 por ejemplo.
wfuzz -R1 --script=links -L -z list,index.html http://192.168.56.101/FUZZEn este caso ponemos -R1 para limitar el nivel de recursividad y lo que sacamos son los links de la pagina de Mr.Robot.

Ademas de los Scripts por defecto podremos escribir nosotros nuestros script, el detalle de como escribir Script para wfuzz lo hablaremos con más detalle en otra entrada igual que cuando hablamos del desarrollos de modulos MetaSploit.
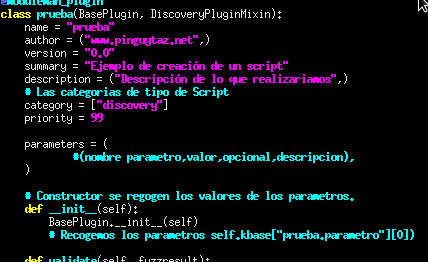
Pero dejamos la plantilla de un Script . Lo colocaremos en el directorio «.wfuzz/scripts» y la extensión del archivo sera .py ya que se codificara en Python.
###############################################################
# Pinguytaz.net
#
# https://www.pinguytaz.net
#
# Descripción: Ejemplo para la creación de script de wfuzz
#
# Historico:
##############################################################
from wfuzz.plugin_api.mixins import DiscoveryPluginMixin
from wfuzz.plugin_api.base import BasePlugin
from wfuzz.externals.moduleman.plugin import moduleman_plugin
@moduleman_plugin
class prueba(BasePlugin, DiscoveryPluginMixin):
name = "prueba"
author = ("www.pinguytaz.net",)
version = "0.0"
summary = "Ejemplo de creación de un script"
description = ("Descripción de lo que realizariamos",)
# Las categorias de tipo de Script
category = ["discovery"]
priority = 99
parameters = (
#(nombre parametro,valor,opcional,descripcion),
)
# Constructor se regogen los valores de los parametros.
def __init__(self):
BasePlugin.__init__(self)
# Recogemos los parametros self.kbase["prueba.parametro"][0])
def validate(self, fuzzresult):
# Se realizara el analisis de si debe procesarse, lo más comun retorno codigo 200
# Cada llamada de FUZZ o solicitud llega y si retornamos True se llama a process
# fuzzresult Es el resultado de la solicitud
# .code es el codigo de retorno
# .chars, .lines, .words, .url
# .content Da el contenido de la pagina, que lo normal es analizarla en process.
return (fuzzresult.code == 200)
def process(self, fuzzresult):
# Se procesa cada vez que validate da un True
# self.queue_url(url) Para encolar otra solicitud
print("Procesa el Script cada vez que validate() retorna True ", fuzzresult.content)Salidas
Hasta el momento hemos visto una simple salida estandar por consola que nos da el código de respuesta, lineas de la pagina devuelta, las palabras y los caracteres.
También nos da el conjunto de payloads (carga útil) utilizados para esa respuesta y que nos sera util para descubrir: usuario, clave, tipo de inyección satisfactoria así como directorios a observar o que nos den información del gestor de contenidos usados.
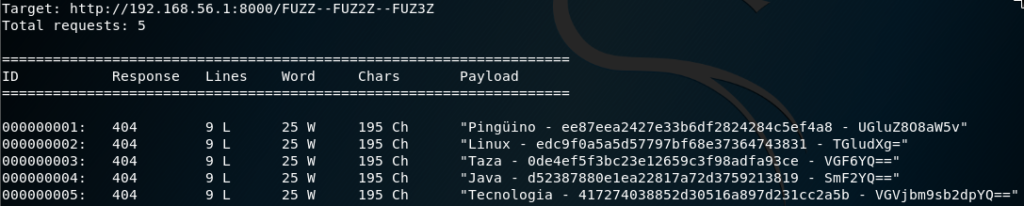
Pues también podremos volcar esta salida a un fichero de diferentes formas con «-f<fichero>,<tipo salida>» sino ponemos el tipo de salida realizaremos un volcado a fichero como el que aparece en consola. Para conocer los tipos de salida ejecutaremos el comendo wfuzz -e printers.
- csv Fichero de texto con cada uno de los campos separado por «,» de forma que lo podemos llevar facilmente a un fichero excell o similar.
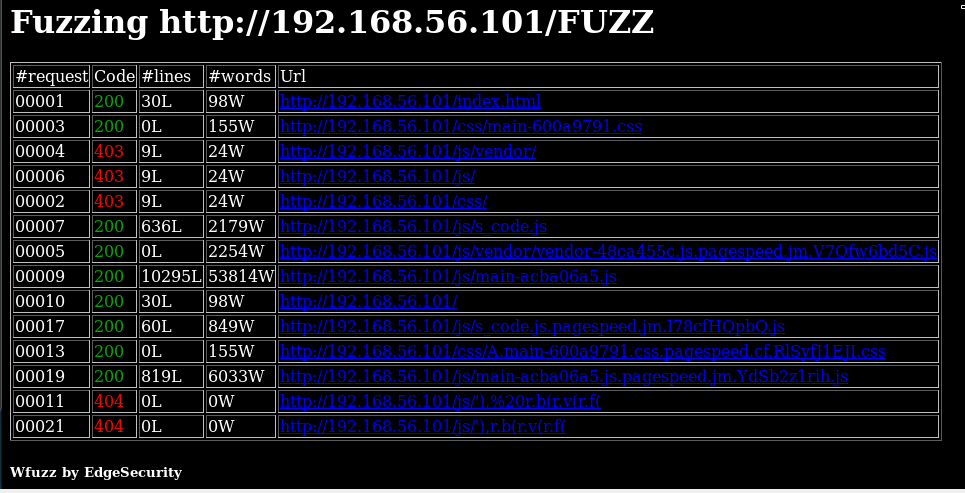
- html Una bonita tabla en HTML con los enlaces activos para que podamos pinchar en ellos.
- json Fichero texto en formato JSON ( JavaScript Object Notation)
- magictree Fichero en formato magictree, que es una herramienta para la gestión de datos en arbol que nos ayuda a concentrar los datos de nuestro análisis de pentesting para luego generar el informe final.
- raw la salida estandar que la enviamos a fichero.
Y con esto finalizamos la explicación de esta versátil herramienta de analisis web para pasar a la siguiente entrada con ejemplos concretos de su uso.